Abstract
In this work, we introduce the Virtual In-Hand Eye Transformer (VIHE), a novel method designed to enhance 3D manipulation capabilities through action-aware view rendering. For each action step, VIHE autoregressively refines a prediction of hand keypoints in multiple stages by conditioning on virtual in-hand views from the predicted hand pose in the previous stage. The virtual in-hand views provide a strong inductive bias for effectively recognizing the correct pose for the hand to be placed, especially for challenging high-precision tasks.
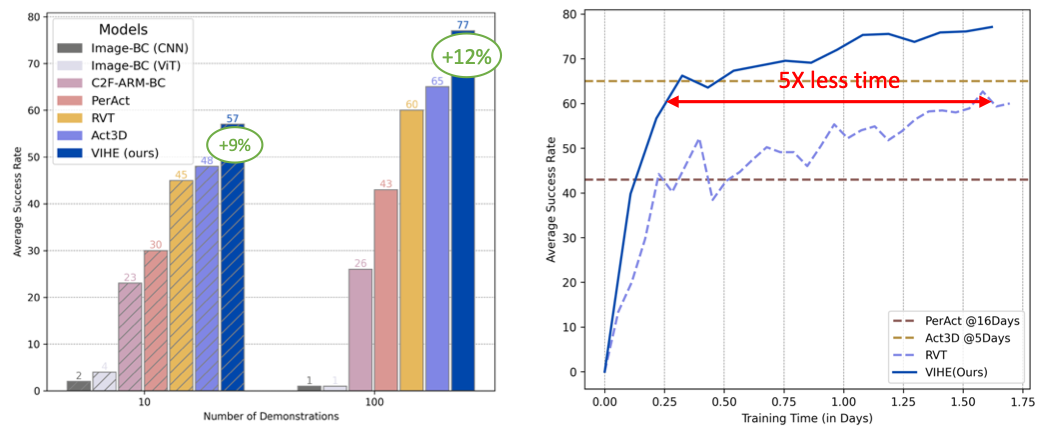
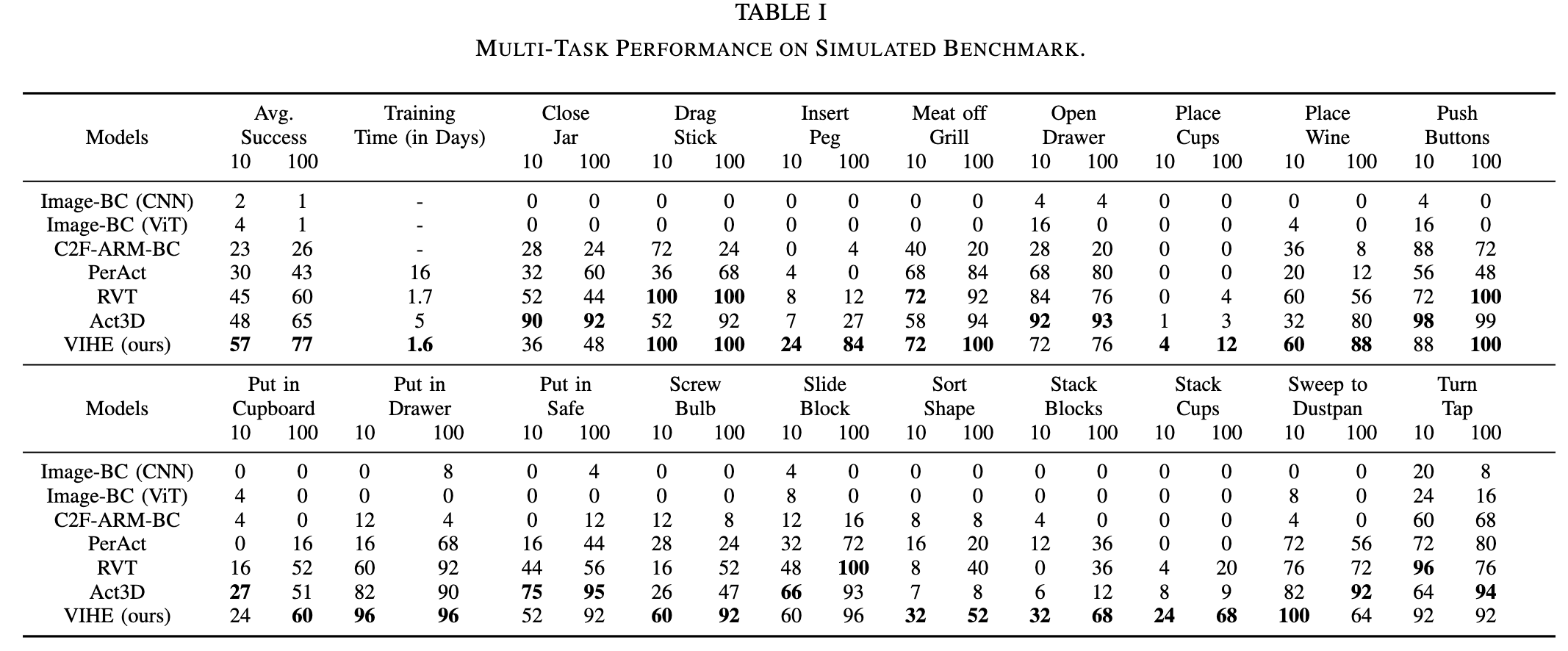
On 18 manipulation tasks in RLBench simulated environments, VIHE achieves the new state-of-the-art with 12% absolute improvement from 65% to 77% over the existing SOTA model using 100 demonstrations per task. Furthermore, our average success rate with only 10 demonstrations per task matches that of the current SOTA methods which use 100 demonstrations per task, making our approach 10 times more sample-efficient.
In real-world scenarios, VIHE can learn manipulation tasks with a handful of demonstrations, highlighting its practical utility.